
Last week I was in Edinburgh at a symposium organised by the CAMARADES research network, which was asking why only 1% of stroke drugs which look good in animal trials end up being effective in humans. (We’ll get to why this matters for toxicological research in a bit.)
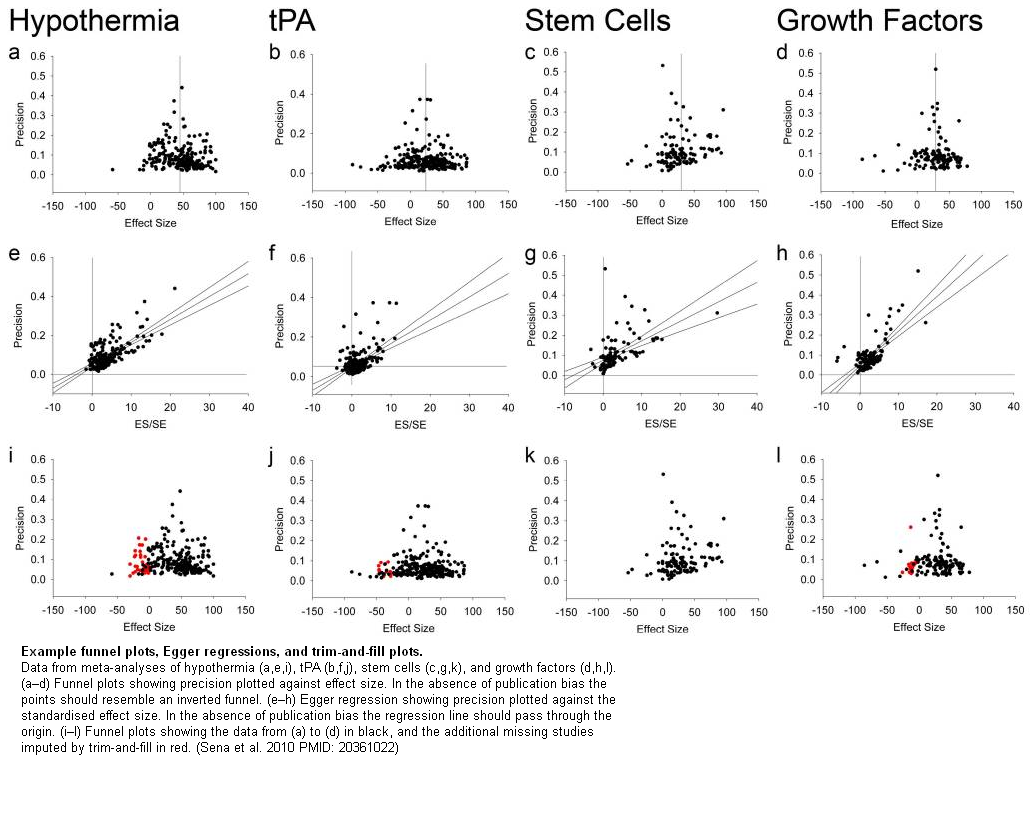
 Various plots which can be used to estimate the magnitude of publication bias. Click to enlarge.
Various plots which can be used to estimate the magnitude of publication bias. Click to enlarge.
The picture of drug development painted at the meeting was pretty grim. In animal trials around 70 compounds (somewhere in the region of 60% of all those tested on animals) look as if they are a good bet for treating ischaemic stroke in humans. Of those 70-odd, however, only 1 has been shown to be at all effective (thrombolysis with recombinant tissue plasminogen activator; for an analysis of its efficacy see Sena et al. 2010).
We can expect a certain failure rate when developing drugs because animal models are limited in what they can tell us about humans: a drug might work in a controlled experimental set-up that simply doesn’t work when tested in a real-world environment where a person might suffering from other diseases, have had a stroke similar but not the same as the one induced in animal tests, or be older than the animals in the test, amongst other reasons.
The concern, however, is that for stroke drugs the failure rate is too high, raising moral and financial issues. Ethically, the use of animals in research must be minimised wherever possible, while people should only be enrolled in clinical trials for drugs for which there is reasonable evidence that it will have a beneficial effect (otherwise their health is put at risk and they are potentially diverted them away from trials of compounds which are more likely to be effective). Financially, drug development is an extremely expensive business, with every failure increasing the cost of finding something that actually works.
We won’t dally on the subject of animal models here, thought their usefulness in stroke research was discussed at the meeting (the consensus view is that although some models can be very weak, careful disease modelling in animals is useful; for a counter-view, see Greek & Menache 2013). What is most interesting for our purposes in this project is the interest in how our impression of the efficacy of a drug (or, for us, the toxicity of chemical) can be changed by how studies are reported.
Publication bias
First of all, there are the problems with publication bias. This is old news – at least, nobody should be surprised by the occurrence of publication bias. What is interesting is the quantification of publication bias presented at the meeting: according to what was reported at the symposium, somewhere in the region of 14-18% of animal trials with negative findings go unpublished.
This has a knock-on effect of overestimating efficacy of test compounds by as much as 30-35%, depending on what is being researched. So this is part of why so many drugs look promising at a pre-clinical stage yet fail to show efficacy in humans, and underlines why steps need to be taken to ensure all animal studies are published regardless of positive or negative result. (For an overview of the impact of animal model and publication bias on perceived drug efficacy, see van der Worp et al. 2010; for specific data on stroke, see Sena et al. 2010)
Power analysis
Secondly, and much more surprising given how fundamental it is, was just how few studies report a power analysis calculation in their method.
Power calculations are necessary to ensure that enough animals are used in a study to produce a result which you can be sure is the product of the experimental set-up rather than just a chance outcome; that if you conduct the experiment several times that it will produce more-or-less exactly the same result each time (in other words, power analysis is an important element of ensuring an experiment is reliable). If a study is underpowered, it greatly increases the likelihood that a result is a random variation rather than caused by the thing you are studying.
It is not necessarily the case that just because a power calculation is not reported that one has not been carried out. However, there is a correlation between something not being reported in a study write-up and it not being done in practice; and (in stroke at least)there is also a suspiciously large number of animal studies which are conducted on 10 specimens or fewer, which may well be too low. If this really is too low, then most compounds will have been put forward to human trials on the basis of chance observations rather than any real effect the compound in question was likely to be having; if drugs are identified on the basis of statistical noise, it should be no surprise that so few of them work.
Implications for toxicological research
In medicine we appear to have a bit of a mess: limitations in animal models combine with publication bias and underpowered studies to produce a body of animal data which, it turns out, is barely fit for the purpose of distinguishing promising stroke drugs from useless ones.
This has important implications for toxicological research.
On the value of animal models, there are the endless arguments about whether or not a given model has been sufficiently validated to be of use in regulatory risk assessment. There are even some arguments that animal models should be ditched from toxicological research altogether (see e.g. Guzelian et al. 2005 and Ruden & Hanssen 2008 for a response). I don’t want to get into this here, save to observe there is an uneasy distinction between what counts as evidence of harm and what constitutes sufficient evidence of harm for informing a risk assessment, a large crack down which research useful research might be falling.
On publication bias, it is not clear the direction in which the overall bias goes. On the one hand, commercial imperatives create little incentive for manufacturers to publish speculative research about the toxicity of their own products, so we could reasonably expect a failure to publish positive findings of toxicity. On the other hand, researchers receiving grant money for studying the toxicity of specific compounds are more likely to publish if they find something and less likely if they do not, so we could also reasonably expect a bias towards publishing positive results.
Either way, the only means for finding out is to analyse the effect publication bias may be having in the literature. Otherwise, on a case-by-case basis, each study can only be assessed for risk of bias according to what it does and does not report regarding its methodology. (At this stage, I don’t personally subscribe to the view that funding source is in itself a bias, rather that funding source creates pressures which can manifest as various types of bias and methodological inadequacies in a study.)
On power analysis, I am not aware of any hard data as to whether or not toxicological research is sufficiently powered. OECD guideline studies stipulate the use of minimum numbers of animals, which is supposed to ensure sufficient power (though power doesn’t help if a study cannot find the effect it is supposed to be looking for, a plentiful source of debate in endocrine disruption).
Regulatory risk assessors have a habit of saying many of the smaller studies are “too small” to be significant but don’t generally state what a sufficient size would be (and at other meetings I have heard researchers saying that 6 animals can be sufficient for determining endocrine disrupting effects from e.g. BPA. Whether OECD groups are unnecessarily large, and whether academic studies are insufficiently powered, I find it at this point impossible to judge.
We clearly need some research into whether or not toxicological studies are in general sufficiently powered, as we are at real risk of either wasting time, money and animals on underpowered research, or incorrectly dismissing from risk assessment as too small studies which are in fact of sufficient size. (Overall, research and reporting recommendations are likely to be similar to those being articulated for animal research in medicine; for an example, see Landis et al. 2012.)
Neither is good because we want the data we use to make decisions about which chemicals we prioritise for regulatory control to be of sufficient quality that we can reliably pick out those which are a problem and put on the back burner those which are less so. We can’t expect to get it right every time, but we need it to be better than luck if we are to make decisions which will protect the environment and human health.